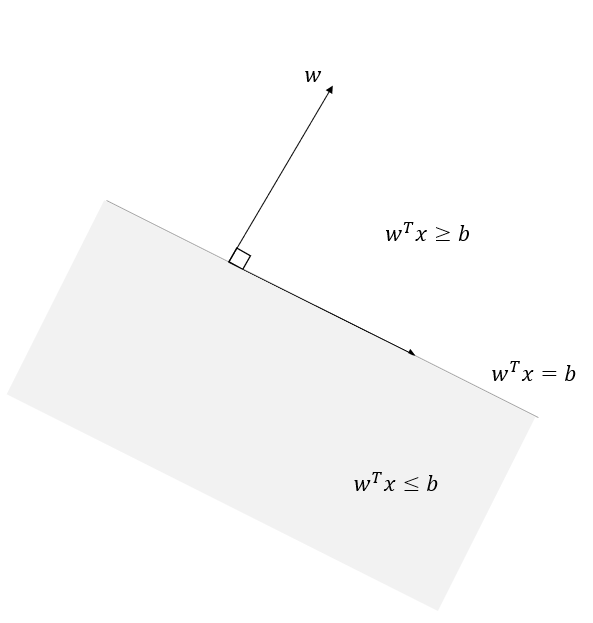
이번 포스팅에서는 최적화 문제에서 널리 쓰이는 방법 중 하나인 Gradient Descent에 대해 알아봅시다. Gradient Descent?Gradient Descent는 머신러닝과 최적화 문제에서 널리 사용되는 방법 중 하나로, 주어진 함수의 최소값을 찾기 위해 사용됩니다. 이 방법은 이름 그대로 cost function의 기울기가 낮은 방향으로 반복적으로 이동하며 최소값을 찾아가는 방법입니다. 기본적으로 최소화하고자 하는 목적 함수(cost function) J(θ)와 입력변수 θ, 그리고 목적함수의 기울기인 ▽J(θ)를 필요로 합니다. 동작 알고리즘Gradient Descent의 동작 알고리즘은 아래와 같이 이루어집니다. 1. ..